HMM分词实现思路
作者: IntoHole | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明
网址: http://www.buyiker.com/2017/04/17/hmm-segmetion.html
网址: http://www.buyiker.com/2017/04/17/hmm-segmetion.html
HMM背景知识
- 状态:隐藏状态、观察状态
- 举例说明:燕子低飞,天要下雨;燕子低飞,我们可以从肉眼直接观察得知的,天要下雨是我们根据这个规律知道内在状态;看到a发生了,那么b很有可能发生
- 维特比算法为什么优良
- n个事情,我们想看那种事情发生概率最大,那么我们可以枚举所有可能,将所有可能计算出来概率,找到一条最大概率路径;这种方法有两个缺点,计算量大,数据稀疏(可以想象成二叉树)
- 有个维特比的人发现,我们为什么要计算所有路径上的概率呢,我们是不是可以只关心状态的前几个发生事情概率最大就可以呢;事实证明这种方法非常可行;所以有了马尔科夫链,计算概率值的时候,只关心当前状态的前n状态
- 生活中我们想透过表象看内在怎么破
- 我们可以用维特比算法计算概率
- 隐藏状态 [健康,发烧];观察状态[身体正常,身体发冷,头眼昏花]
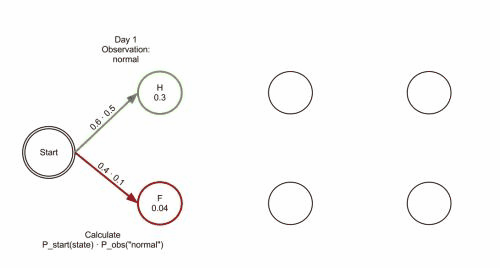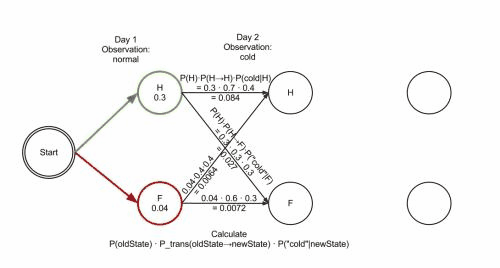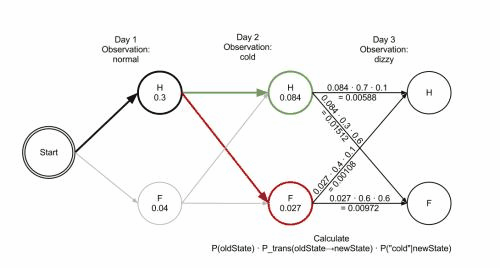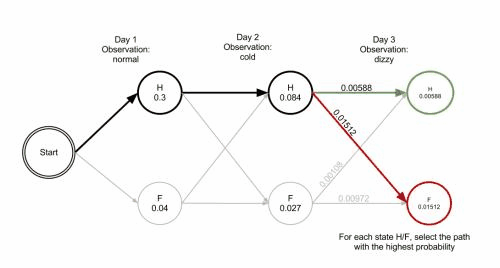
- 我们知道隐藏状态,观察状态了,那么我们要得知几个矩阵,隐藏状态开始概率矩阵,隐藏状态与隐藏状态转移概率矩阵,观察状态对应隐藏状态矩阵;
- 开始状态矩阵,就是我们根据统计,得知在第一个观察状态在各个隐藏状态发生的概率;
- 我们可以通过计算相应的观察状态,每种隐藏状态下发生概率,类似取得最大路径算法,我们计算出多n步,看这个路径下哪条路径概率发生最大,保留这个路径下的隐藏状态,直到最后一步计算出隐藏状态结束;
分词思路
- 定义隐藏状态
- S(词的开始)、M(词的中间)、E(词的结尾)、W(单子词)
- 定义观察状态
- 我(W) 爱(W) 中(S)国(M)母(M)亲(E) !(W)
- 我们需要一个事先分好词的语料,我们通过程序将每个字处理上面的格式
- 通过计算出开始状态概率矩阵,其实就是统计每个字出现在开头对应隐藏状态比率;对应隐藏状态与下个隐藏状态之间概率值,统计数字就可以;统计出观察状态(某个字)对应的隐藏状态(MESW)概率;
- 统计出这个矩阵+维特比算法,就可以将文章进行分词;
参考信息