Hadoop Streaming 编写
作者: IntoHole | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明
网址: http://www.buyiker.com/2015/05/02/hadoop-streaming-write.html
网址: http://www.buyiker.com/2015/05/02/hadoop-streaming-write.html
Hadoop Streaming 编写
Mapreduce
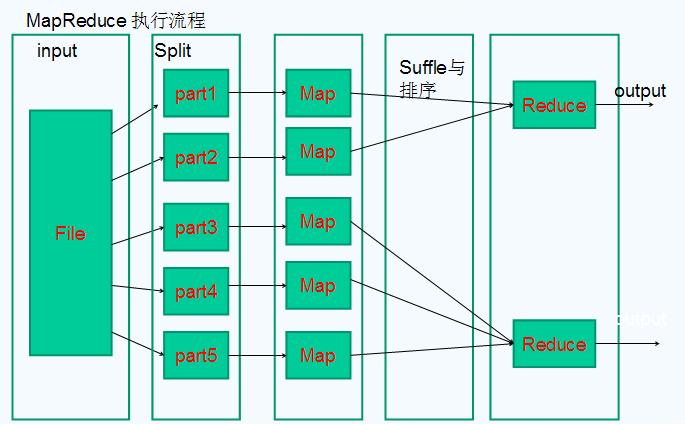
- 可以这样比喻一下,有很多副牌,打乱了,老板让你重新整理好【规规整整】;你现在一个做不来!除非你是哪吒!怎么办呢?
- 你有很多伙伴,你们每个人拿了很多牌【等量的】(map)
- 你告诉他们把每种牌,不分花色【2,3,4,5,6,。。大王,小王】都放在一个盒子里(suffle,相同key都放在一个筒子里)
- 等1,2步骤弄好了,你随机获得一个盒子【要把相同的牌,按照花色排序】(reduce)
Hadoop Streaming 命令行
$HADOOP_HOME/bin/hadoop jar streaming
options:
(1)-input:输入文件路径
(2)-output:输出文件路径
(3)-mapper:用户自己写的mapper程序,可以是可执行文件或者脚本
(4)-reducer:用户自己写的reducer程序,可以是可执行文件或者脚本
(5)-file:打包文件到提交的作业中,可以是mapper或者reducer要用的输入文件,如配置文件,字典等。
(6)-partitioner:用户自定义的partitioner程序
(7)-combiner:用户自定义的combiner程序(必须用java实现)
(8)作业的一些属性(以前用的是-jonconf)
1)mapred.map.tasks:map task数目
2)mapred.reduce.tasks:reduce task数目
3)stream.map.input.field.separator/stream.map.output.field.separator: map task输入/输出数据的分隔符,默认均为\t。
4)stream.num.map.output.key.fields:指定map task输出记录中key所占的域数目
5)stream.reduce.input.field.separator/stream.reduce.output.field.separator:reduce task输入/输出数据的分隔符,默认均为\t。
6)stream.num.reduce.output.key.fields:指定reduce task输出记录中key所占的域数目
streaming 程序编写
#这是一个python版本hadoop streaming[Map|reduce]
import sys
for line in sys.stdin:
lineArray = line.strip().split('\t') #解析数据
#如果是reduce , 数据是有序的,按照顺序处理相同key就可以了
#dosomthing
#数据什么样的分隔符,可以在hadoop streaming 进行设置 , 但是程序还是会读入行;你要做的
- Map
- 把输入的数据变成key\tvalue1\tvalue2….valueN
- Reduce
- 输入数据是有序的【key相同数据,按照顺序读入】
Trick
- 在linux中模拟mapreduce
cat data.txt | python map.py | sort | python reduce.py #输入数据,在map里处理,管道输出,sort排序后,reduce进行处理参考