一个简单的爬虫架构
作者: IntoHole | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明
网址: http://www.buyiker.com/2014/07/29/spider-design.html
网址: http://www.buyiker.com/2014/07/29/spider-design.html
一个分布式爬虫的设计
- 设计一个可以分布式爬取网站的爬虫
- 设计流程
- 设计一个简单的架构
爬虫逻辑流程图
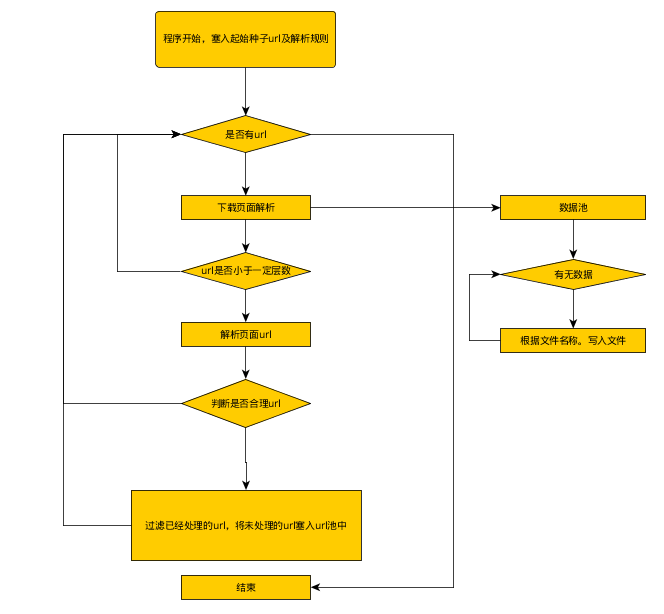
爬虫架构图
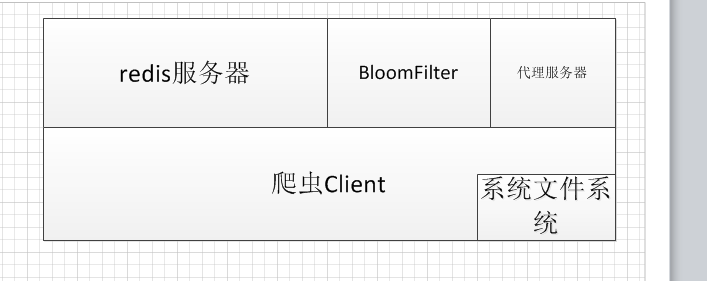
设计逻辑
- 基于广度遍历网页 (设置层数限制)
- 利用redis 实现爬虫队列(先进后出 lpush , rpop)
- 利用redis bloomfilter 验证是否爬取网址(速度快 , 分布式 , 缺点 : 有容错率 , 但是网络爬虫可以容忍这个问题)
- bloomfilter 原理
- 文件写入方式 , 基于 队列 , 定时刷新文件
- 利用谷歌goaget ,访问,被墙页面 (技术自己搜)
扩展
- 因为深度遍历网页时 , 通过获取 a href, 会存在pdf等网页杂音 , 必须滤过
- 基于论坛 , 可以先遍历 , 主网页 , 获得每个分论坛页面url , 在获取 每个网页分论坛的网址 , 提高网页爬虫利用率
- 分布式爬取 , 就是利用了redis , 实现队列 ,而使每个爬虫客户端可以不用管其他爬虫 ,redis分布式,避免原来瓶颈是主服务器
总结
设计流程 , 编写主流程代码 , 大约三小时,满足基本需求 , 因为特定需求,设计的